本节基本就是router.py这个模块的一一对应,需要加深理解最好打开源代码一边看代码一边看说明(本文针对Pyramid 1.3b2代码)。
上一篇说了Pyramid项目里main函数使用make_wsgi_app生成了一个名字叫Router的app,并将这个app传给了WSGI服务器。那么,显而易见,Pyramid处理Request请求就是跟这个Router类息息相关了。
1. WSGI服务器一旦接受到用户请求,即按照规范要求构造WSGI环境变量,然后将这些变量传递给router对象(app)的__call__方法。(参见paste deploy)
2. router使用request_factory创建一个request对象,并将WSGI环境变量传递给request对象。从这种处理方式可以看出,我们甚至可以自定义一个定制化的request_factory,以便生成特有的request。(参加router.py 179行)
3. 将request、registry对象放入到thread local栈中,以使每次请求之间的数据不会有冲突。今后可以用get_current_request()、get_current_registry()来得到这两个对象,不过在view中建议采用直接采用request、request.registry。(参加router.py 180-183行)
4. 触发一个NewRequest事件。(参加router.py 75行)
5. 如果在之前的应用配置处(main函数)配置了route配置项,Pyramid会调用routes_mapper函数进行URL分发。该函数检查预定义的route中(main函数)是否有与request包含的当前WSGI变量相匹配的项。(参加router.py 79行)
6. 如果找到匹配项,route_mapper函数会在request中加入两个属性:matchdict、matched_route。matchdict是一个针对具体PATH_INFO与预定义route项匹配之后形成的动态参数。比如定义了add_route(’idea’, ’site/{id}’),那么/site/1请求就会形成一个值为{’id’:’1’}的matchdict。matched_route则是指对应的那条route对象(参加router.py 94-95行)。随后,生成该route对应的root对象(参加router.py 120行)。如果这条route中配置了factory,则采用该factory生成root对象,否则采用默认的root_factory。(参见48、77、118行)
7. 如果没有找到相匹配的route,而且在创建Configurator对象时指定了root_factory参数,则使用该root_factory创建root对象。如果没有指定root_factory参数,则使用DefaultRootFactory来创建root对象。(参见48、77、118行)
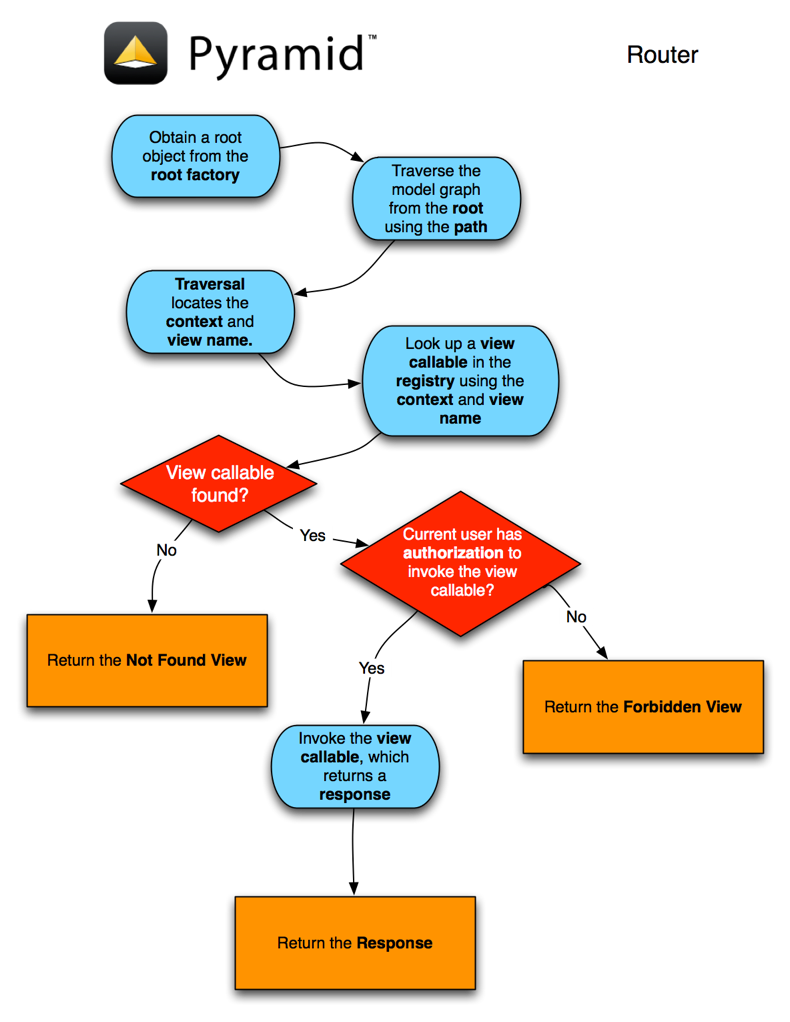
8. Pyramid通过root、request参数漫游(traverser),traverser从root对象开始漫游(__getitem__方法)以寻找合适的context,如果root对象没有__getitem__方法,则将root对象赋给context。traverser返回一个带context、view名字等信息的字典。(参加router.py124-136行)
9. 将上一步取得的参数添加到request对象中,因此在view代码中,可以用request.context这种方式来访问他们。(参见router.py 138行)
10. 触发contextFound事件(参见router.py 139行)
11. 使用context、request、view名字等信息查找view,如果找不到,则抛出HTTPNotFound 异常(参见router.py 141-162行)
12. 如果找到了合适的view,Pyramid查看是否已经定义了认证策略,且这个view配置了访问权限。如是,则Pyramid将request中的访问者凭证与context附带的安全信息进行匹配,如果匹配通过,Pyramid则调用该view并且获得response对象。否则抛出HTTPForbidden异常。
13. 如果在上述过程中(root factory、traversal、view)抛出了异常,如HTTPNotFound、 HTTPForbidden,router将捕获这些异常,并赋给request.exception属性。然后寻找一个合适该异常的view,如果有这样的view,就调用它,产生response对象。如果找不到,就抛出该异常。
14. 触发NewResponse事件(参见router.py 188行)
15. 当一个response对象通过view或exception view生成之后,Pyramid将会遍历执行所有通过add_response_callback方法加进来的方法、对象。(参加 router.py 190-192 行)
16. 遍历执行通过add_finished_callback加入进来的方法、对象。(参见router.py 196-197 行)
17. 将threadlocal从栈中弹出。(参见 router.py 200 行)