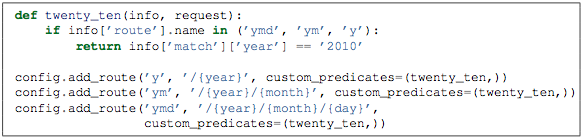
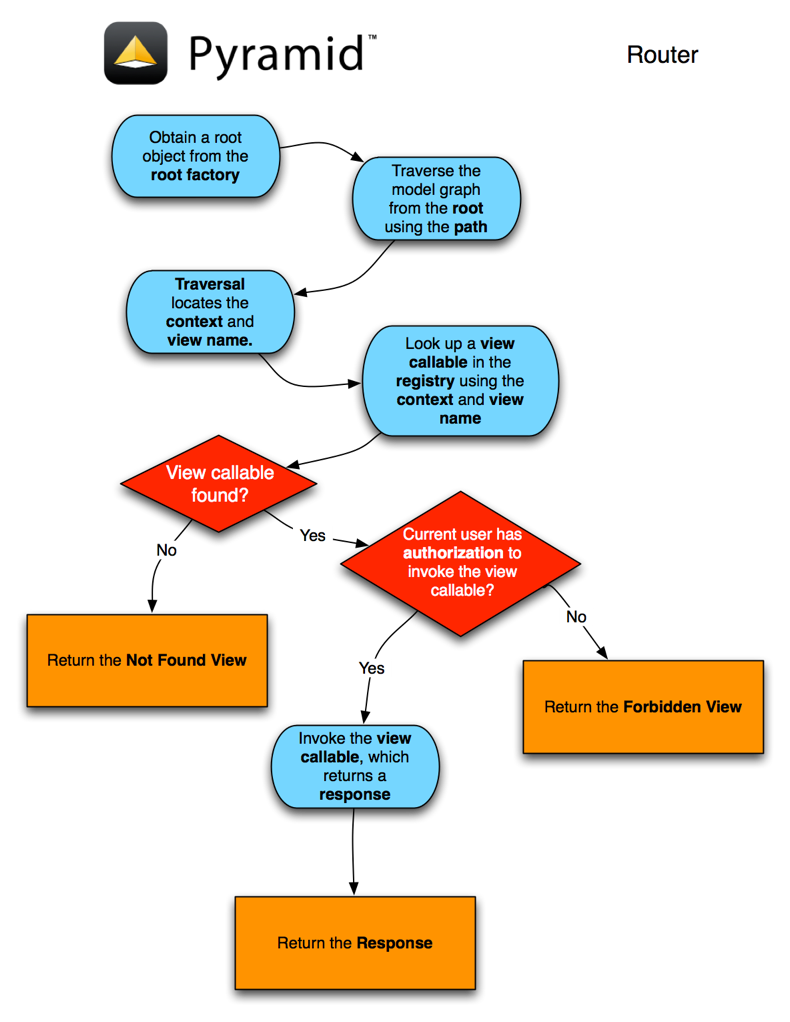
四、一个复杂的案例
models.py
---------------------------
from sqlalchemy import (
Column,
Integer,
Text,
and_,
)
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import (
scoped_session,
sessionmaker,
)
from zope.sqlalchemy import ZopeTransactionExtension
DBSession = scoped_session(sessionmaker(extension=ZopeTransactionExtension()))
Base = declarative_base()
class MyCat(Base):
__tablename__ = 'mycat'
id = Column(Integer, primary_key=True)
name = Column(Text, unique=True)
pid = Column(Integer)
desc = Column(Text)
def __init__(self, name, pid, desc):
self.name = name
self.pid = pid
self.desc = desc
def __getitem__(self, key):
session= DBSession()
is_file = False
try:
key.index(".")
is_file = True
except: pass
if is_file:
item = session.query(MyFile).filter(and_(MyFile.name==key, MyFile.cat==self.id)).first()
else:
item = session.query(MyCat).filter(and_(MyCat.name==key, MyCat.pid==self.id)).first()
if item is None:
raise KeyError(key)
item.__parent__ = self
item.__name__ = key
return item
def get(self, key, default=None):
try:
item = self.__getitem__(key)
except KeyError:
item = default
return item
def listall(self):
session= DBSession()
cats = session.query(MyCat).filter(MyCat.pid==self.id).all()
files = session.query(MyFile).filter(MyFile.cat==self.id).all()
return cats + files
class MyFile(Base):
__tablename__ = 'myfile'
id = Column(Integer, primary_key=True)
name = Column(Text, unique=True)
cat = Column(Integer)
save_path = Column(Text)
desc = Column(Text)
def __init__(self, name, cat, save_path, desc):
self.name = name
self.cat = cat
self.save_path = save_path
self.desc = desc
class MyRoot(object):
__name__ = None
__parent__ = None
def __getitem__(self, key):
session= DBSession()
item = session.query(MyCat).filter(and_(MyCat.name==key, MyCat.pid==0)).first()
if item is None:
raise KeyError(key)
item.__parent__ = self
item.__name__ = key
return item
def get(self, key, default=None):
try:
item = self.__getitem__(key)
except KeyError:
item = default
return item
def __iter__(self):
session= DBSession()
query = session.query(MyCat).filter(MyCat.pid==0)
return iter(query)
root = MyRoot()
def root_factory(request):
return root
views.py
--------------------------
from .models import (
DBSession,
MyCat,
MyFile,
)
def view_root(context, request):
print request.resource_url(context)
return {'context':context, 'items':list(context), 'project':'MyTest'}
def view_cat(context, request):
print request.resource_url(context)
return {'context':context, 'items':context.listall(), 'project':'MyTest'}
def view_file(context, request):
print request.resource_url(context)
return {'item':context, 'project':'MyTest'}
def view_photo(context, request):
return {'item':context, 'project':'MyTest'}
__init__.py
--------------------------
from pyramid.config import Configurator
from sqlalchemy import engine_from_config
from .models import (
DBSession,
root_factory,
)
def main(global_config, **settings):
""" This function returns a Pyramid WSGI application.
"""
engine = engine_from_config(settings, 'sqlalchemy.')
DBSession.configure(bind=engine)
config = Configurator(settings=settings, root_factory=root_factory)
config.add_static_view('static', 'static', cache_max_age=3600)
config.add_view('traverseonrdb.views.view_root',
context='traverseonrdb.models.MyRoot',
renderer="templates/root.pt")
config.add_view('traverseonrdb.views.view_cat',
context='traverseonrdb.models.MyCat',
renderer="templates/cat.pt")
config.add_view('traverseonrdb.views.view_photo',
name="photoview",
context='traverseonrdb.models.MyFile',
renderer="templates/photo.pt")
config.add_view('traverseonrdb.views.view_file',
context='traverseonrdb.models.MyFile',
renderer="templates/file.pt")
return config.make_wsgi_app()
populate.py
--------------------------
# -*- coding: UTF-8 -*-
import os
import sys
import transaction
from sqlalchemy import engine_from_config
from pyramid.paster import (
get_appsettings,
setup_logging,
)
from ..models import (
DBSession,
MyCat,
MyFile,
Base,
)
def usage(argv):
cmd = os.path.basename(argv[0])
print('usage: %s <config_uri>\n'
'(example: "%s development.ini")' % (cmd, cmd))
sys.exit(1)
#直接在数据库中构建如下初始数据以供演示。
#MySite ---- MyPhoto ---- SportPhoto ---- ski.jpg
# | |
# | -- PrivatePhoto ---- love.jpg
# |
# -- MyNote ---- 20120327.txt
# |
# -- MyMP3 ---- paradise.mp3
# |
# -- MyVideo ---- hot.avi
def main(argv=sys.argv):
if len(argv) != 2:
usage(argv)
config_uri = argv[1]
setup_logging(config_uri)
settings = get_appsettings(config_uri)
engine = engine_from_config(settings, 'sqlalchemy.')
DBSession.configure(bind=engine)
Base.metadata.create_all(engine)
with transaction.manager:
my_photo_cat = MyCat(name='MyPhoto', pid=0, desc="photos taken by myself")
DBSession.add(my_photo_cat)
my_note_cat = MyCat(name='MyNote', pid=0, desc="take a note a day to save life")
DBSession.add(my_note_cat)
my_mp3_cat = MyCat(name='MyMP3', pid=0, desc="my favorite mp3")
DBSession.add(my_mp3_cat)
my_video_cat = MyCat(name='MyVideo', pid=0, desc="all my hot videos")
DBSession.add(my_video_cat)
DBSession.flush()
my_sport_photo_cat = MyCat(name='SportPhoto', pid=my_photo_cat.id, desc="photos of sports")
DBSession.add(my_sport_photo_cat)
my_private_photo_cat = MyCat(name='PrivatePhoto', pid=my_photo_cat.id, desc="secret photos")
DBSession.add(my_private_photo_cat)
DBSession.flush()
afile = MyFile(name='ski.jpg', cat=my_sport_photo_cat.id, save_path="", desc="20111112 by canon")
DBSession.add(afile)
afile = MyFile(name='love.jpg', cat=my_private_photo_cat.id, save_path="", desc="20111111 by canon")
DBSession.add(afile)
afile = MyFile(name='20120327.txt', cat=my_note_cat.id, save_path="", desc="diary 20120327")
DBSession.add(afile)
afile = MyFile(name='paradise.mp3', cat=my_mp3_cat.id, save_path="", desc="mp3 download")
DBSession.add(afile)
afile = MyFile(name='hot.avi', cat=my_video_cat.id, save_path="", desc="hot video from some place")
DBSession.add(afile)
详细代码参见:
https://github.com/eryxlee/pyramid_koans/tree/master/traverseonrdb